
Python基础架构
在第二章 Python 基础架构中主要有四个部分:
- 包管理器conda
- 虚拟环境 conda
- Docker容器
- 云实例
引言
在介绍conda之前,我们再介绍一下Pyhton。
在大家刚开始学习 Python的时候,一定会学到 “Python是一门解释型的语言”。
首先,什么是解释型语言呢,编程语言其实可以分为两大类:
- 编译型
- 解释型。
编译型语言有C、C++等等,编译型语言的特点是:一次编译、永久运行。因为我们编写的源代码都是计算机无法识别的高级语言,因此通过编译过程,将源代码翻译成机器码,然后就可以直接运行,特点就是运行效率高,速度快。
而解释型语言比如 Basic 语言,它的特点是边运行边解释,每执行一次都要翻译一次,因此效率比较低。
那为什么刚才的解释型语言我们举了 Basic 语言的例子但是没有说大家最熟悉的Python呢?事实上,随着越来越多语言的出现,语言的类型早就不止这两种了,我们一般说是解释型语言的Python,实际上并不是一种纯解释的语言,而是一种“编译解释语言”,即先编译、后解释。
Python的编译过程和C、C++的编译不同。一方面,Python是通常是逐模块(逐文件)编译的,而不是编译整个源代码,当导入一个模块或软件包时,Python会编译该模块或软件包的源代码,并将其存储在.pyc文件中,而并不是编译所有的源代码;另一方面,Python编译结果是字节码而不是机器码。
而在Python程序运行时,它会同时对未编译的源代码和编译后的机器码进行逐行解释并运行。
那么为什么Python的运行过程这么怪呢,事实上对于标准Python,它是完全通过解释运行的,但是标准Python只带有标准库,如基础的数学库,输入输出等。各种功能强大的软件包必须独立安装,比如 web 相关的 django、flask,数学相关的 numpy,人工智能相关的 pytorch ……
而正因为有大量的软件包,并且不同软件包:
- 下载方式不同
- 编译、构建条件不同
- 相关依赖不同
- 版本众多
因此,我们必须要有一个工具来管理这些软件包,软件包管理工具应运而生~
软件包管理器
事实上,对于初学 Python的同学,大家接触到的第一个包管理器必然是 pip 而不是 conda ,因此,我们先来看看 pip 。
pip 包管理器
pip 的主要目的是帮助Python开发者轻松管理项目所需的依赖项。通过pip,可以方便地安装第三方Python库、工具和应用程序。
特点
官方包仓库:pip 默认使用Python Package Index(PyPI)作为官方包仓库。PyPI是一个庞大的Python软件包存储库,包含了成千上万的Python软件包,涵盖了各种领域,从Web开发到数据科学和机器学习。
简单的命令:
pip提供了一组简单而直观的命令。自动依赖解决:
pip能够自动解决软件包之间的依赖关系。虚拟环境支持:虽然
pip本身不提供虚拟环境管理功能,但通常与 virtualenv 或 venv 结合使用,以创建和管理独立的Python虚拟环境。版本控制:
pip允许您安装特定版本的软件包,可以确保依赖关系升级和卸载:
pip不仅可以用于安装软件包,还可以升级和卸载软件包。社区支持:
pip是Python社区的一部分,受到广泛的支持和使用。这意味着有大量的文档、教程和社区资源可供参考和求助。
常用命令
Python的安装包中带有 pip,因此在安装 Python 后,我们可以直接使用 pip 进行软件包的管理,几条常用命令如下:
安装包
1
pip install package_name==version
package_name:要安装的软件包名称。version(可选):要安装的特定版本号。
升级包
1
pip install --upgrade package_name
package_name:要升级的软件包名称。
卸载包
1
pip uninstall package_name
search_term(可选):要搜索的关键字。
搜索包
1
pip search search_term
search_term(可选):要搜索的关键字。
列出已安装的包
1
pip list
查看软件包信息:
1
pip show package_name
package_name:要查看信息的软件包名称。
安装依赖项文件
1
pip install -r requirements.txt
requirements.txt:包含依赖项列表的文本文件。
1
2
3
4
5
6
7
8
9
10
11
12
13requirements.txt
asgiref==3.5.2
channels==3.0.2
Django==4.1
html2text==2020.1.16
Markdown==3.4.4
numpy==1.25.2
pdfkit==1.0.0
PyJWT==2.8.0
PyJWT==2.8.0
PyMySQL==1.1.0
pypandoc==1.11
python_docx==0.8.11更换下载源
由于一些众所周知的原因,直接用
pip连接官方仓库经常卡的一批,这个时候我们可以使用国内镜像源(如清华镜像源等)来下载~1
2临时更换
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple package_namepackage_name为包名
如果要永久更换,就需要更改
pip的配置文件pip.ini或者pip.conf,文件路径如下:1
2
3
4
5
6
7
8windows
C:\Users\YourUserName\pip\pip.ini
macOS
~/Library/Application Support/pip/pip.conf
linux
~/.pip/pip.conf打开文件后加入如下内容:
1
2[global]
index-url = https://pypi.tuna.tsinghua.edu.cn/simple/
Conda 包管理器
conda 、 MiniConda 、 Anaconda 他们之间到底有什么关系呢?
和 pip 一样, conda是一个包管理工具,pip有的功能,conda都有。并且:
- 它可以用于管理任何编程语言的软件包,不仅仅是Python
conda本身并不包含任何软件包,但可以用于安装其他软件包。conda支持虚拟环境,可以创建独立的Python环境,以隔离不同项目的依赖关系。
而 MiniConda 、 Anaconda 则是 conda 的不同发行版本。
Miniconda 是一个最小化的conda发行版,它只包含了conda本身和一些基本的库和依赖项,没有任何其他附加的软件包,特点是 轻量。
Anaconda 是一个完整的数据科学和科学计算发行版,它包含了大量的Python软件包、库和工具,用于数据分析、机器学习、科学计算等领域。
与Miniconda相比,Anaconda更大、更全面,并且包括了众多数据科学工具,它占用的硬盘也很恐怖,截至写作为止,Anaconda四个虚拟环境占用了我笔记本25G硬盘,而服务器上的 Miniconda 两个环境只占了 956MB 硬盘 (#_<-)
Miniconda 安装
首先在命令行中输入 Python -V 查看当前 python 环境版本。
接下进入 Miniconda 的官网,找到对应 python 环境版本和操作系统版本并下载。
把文件传输到服务器或者下载到自己的电脑,打开安装文件的文件目录(如果是服务器则 cd 到对应文件目录)
- Windows 直接双击
.exe文件 - MacOS 直接双击
.pkg文件 - Linux则运行命令
bash filename
接下来只要跟着指引一路确认或者回车即可安装成功 (´▽`ʃ♡ƪ)
安装完成后运行 conda list 命令即可查看虚拟环境(一开始应该只要有 base 环境)
Anaconda 安装
直接进入 Anaconda 的 官网 或 清华镜像 选择对应操作系统版本并进行下载
安装过程与 Miniconda 类似,但是记得在安装步骤中勾选添加至环境变量中
安装完成后运行 conda list 命令即可查看虚拟环境(一开始应该只要有 base 环境)
conda 包管理器常用命令
conda 作为包管理器,也和 pip 一样有一些常用的命令:
安装包:
1
conda install package_name==version
package_name:要安装的软件包名称。version(可选):要安装的特定版本号。
更新包:
1
conda update package_name
package_name:要升级的软件包名称。
移除包:
1
conda remove package_name
package_name:要移除的软件包名称。
搜索可用包:
1
conda search package_name
package_name:要搜索的软件包名称。
列出已安装的包:
1
conda list
显示环境中的包信息:
1
conda list --name myenv
myenv:要查询的环境名
显示包的详细信息:
1
conda info package_name
package_name:要查看的软件包名称。
可以看到, conda 作为软件包管理器的命令和 pip 是差不多的,但是,相比较 pip ,conda 有一个巨大的缺陷,即它的软件包存储库远远小于 pip 。 但是, conda 是完全兼容 pip 的,也就是说,我们可以在 conda 的虚拟环境中使用 pip 进行软件包的安装,混用当然会带来一些可能的问题:
conda和pip管理的包可能具有不同的依赖关系,导致包冲突。可能会导致难以解决的问题,例如包无法正常工作或环境不稳定。conda创建的环境和pip安装的包之间可能存在不一致,这可能会导致环境中的包出现问题。
总之,虽然有各种原因不推荐混用。但我混用至今确实没有问题★,°:.☆( ̄▽ ̄)/$:.°★ 。,pip 确实是很方便~
作为虚拟环境管理器的 conda
其实说了这么多,我们会发现作为包管理器,用 pip 就完全足够了,那么为什么还要用 conda 呢,因为它有一个非常牛逼的功能——虚拟环境。
不妨考虑一个问题:
现在有不同的项目需要在同一个服务器上运行,项目一需要 Python >= 3.8 的环境,因为其中有一个核心的算法模型只支持 3.8 及其以上的 Python 版本,而项目二需要 Python <= 3.7 的环境,因为其中有一个拓展包并没有随着 Python 版本的更新而进行维护,导致 Python 3.7 及其以上的环境不支持该拓展包的使用,那么我们该怎么处理呢?
- 方法 1
要用哪个就把另一个软件包给卸载了,但是问题是这样同时只能有一个项目在运行,完全无法满足需求,也会导致服务器的性能浪费。
- 方法 2
让这两个不同的项目在两个不同的环境中运行,单独给其配置环境就可以了,将两个项目的环境区别开来,互不影响,这样就可以在同一个服务器上进行不同项目的部署了。
给不同项目单独配置的环境叫做虚拟环境,管理虚拟环境的工具就是 conda
虚拟环境管理器 conda 常用命令
创建一个新的Conda环境:
1
conda create --name myname python=<version>
myname:创建环境的名称<version>:需要的python版本
激活一个Conda环境:
1
conda activate myenv
myname:使用环境的名称
退出当前的Conda环境(回到base环境):
1
conda deactivate
列出所有已创建的Conda环境:
1
conda info --env
删除一个conda环境(会连同环境中的包一起删除):
1
conda env remove --name myenv
myname:要删除环境的名称
导出环境到文件:
1
conda env export > file_name
file_name:文件名
从一个文件中创建环境
1
conda env create -f file_name
file_name:文件名
Docker容器
引言
在我们学院的指导书上, docker 的使用有37页pdf ……. 所以在这里我就简略一点说了。
在介绍 docker 之前,我们已经介绍完了 conda 虚拟环境,已经几乎完美的解决了本地开发环境的问题,但是注意,只是本地开发。
在真正的开发过程中,项目必须在多台电脑、服务器上运行,如果仍然使用 conda 虚拟环境,就会面临如下情况:
每次转移项目文件都要重新构建环境
太多虚拟环境可能会出现冲突最后不得不重装系统
还有很多其他情况:
我想下载和使用一个软件,所有步骤都按照官方Guide一步步执行,但最后就怎么也启动不 了,总是会报这样或那样的错误(经常用npm 的同学应该深有体会)。
我想下载和使用一个软件,结果总是提示依赖库缺失或版本冲突,最后好不容易解决了, 结果把自己本地的环境搞的一团糟,甚至最后不得不重装系统。
我在本地写好的代码,明明我的机器上跑的好好的,怎么到你那里就有bug了 ? ! !
从网上下载好的一个来源不明程序,莫名奇妙地向你申请各种系统权限,不给权限就罢工。
容器(Container)
为了解决这种大量的环境问题,我们可以使用虚拟机技术来解决,每个虚拟机都有独立的虚拟硬件,操作系统,环境等等。
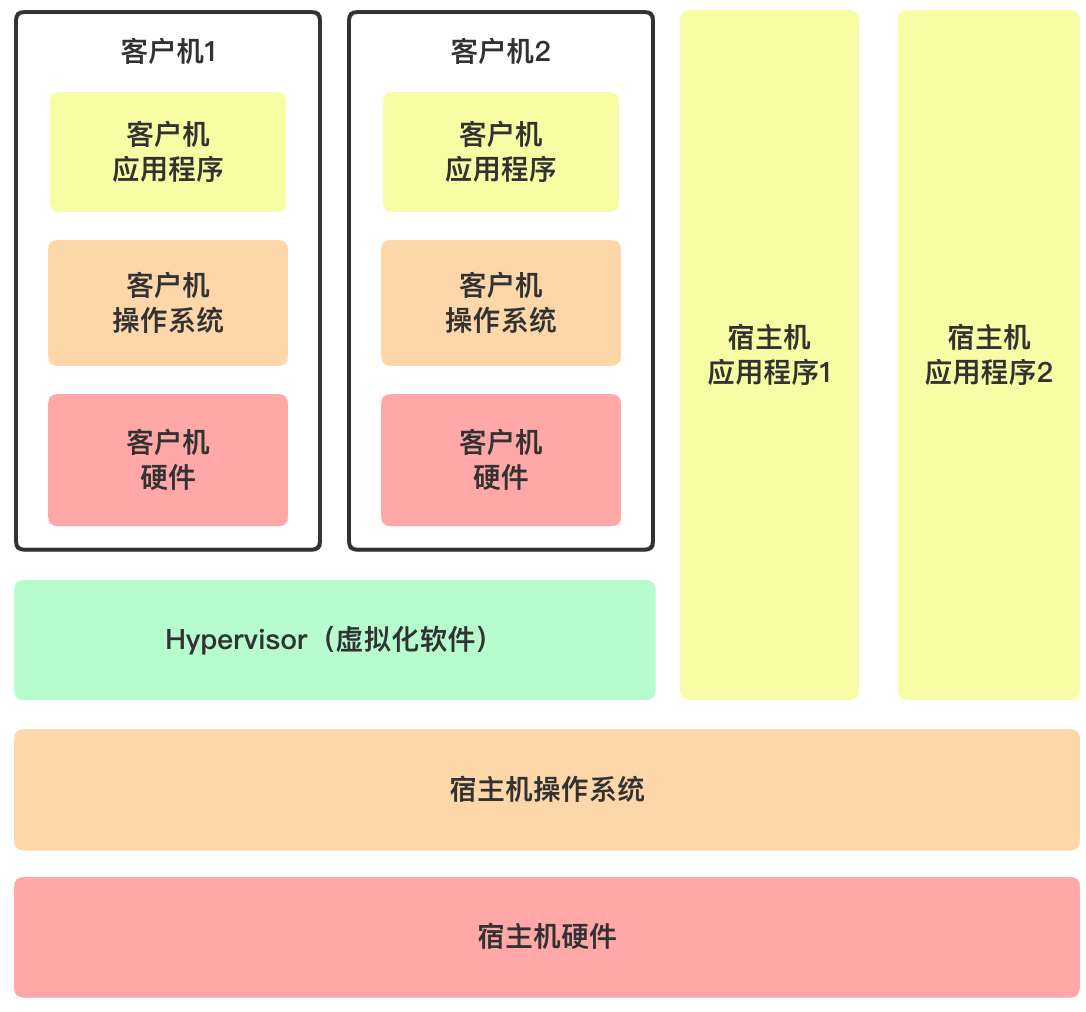
但是,如果每运行一个项目就新建一个虚拟机未免太过奢侈,因为虚拟机需要模拟硬件、还需要有操作系统,而这些所占用的资源实际上远远大于项目运行所需。因此,产生了更轻量级的能够隔离两个不同的应用程序的解决方案——容器。
在Linux中,可以使用 namespace 和 cgroups 机制隔离一个或一组进程。至于 namespace 和 cgroups 机制到底是什么,在这里就不详述了,如果有兴趣的可以在这里查看容器实现环境隔离的具体原理。
我们把这样的一个或一组被隔离的进程称作 “容器 (Container)“ 。 当我们提到“启动(或创建)一个容器”时,其实就是在说“使用 namespace 和 cgroups 机制创建一个或一组进程”。
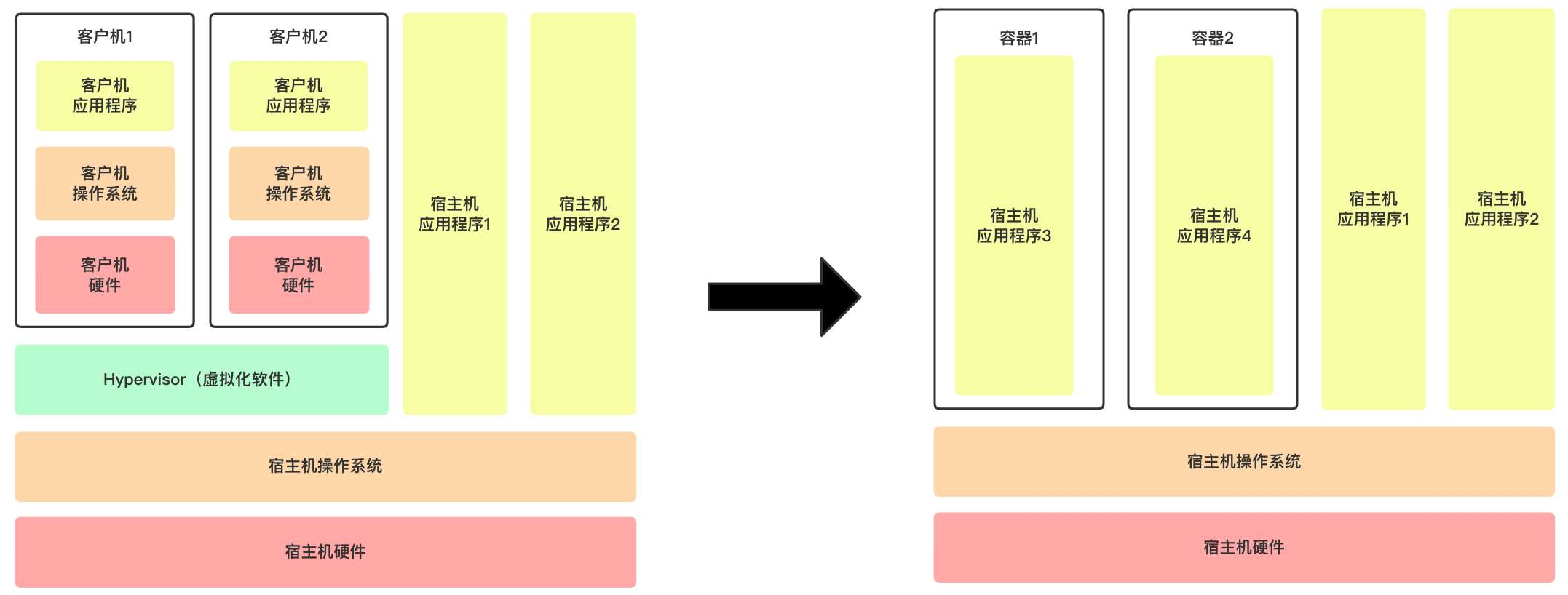
虚拟机和容器的最大的区别在于,虚拟机模拟了一整个计算机环境,其上有一个完整的操作系 统,它有自己的进程调度、内存管理等;而容器仅仅是被隔离的一个或一组进程,这些进程和在宿主操作系统看来跟其他普通进程没什么区别,他们会被Kernel以同样的方式调度,以同样的方式使用内存管理。
镜像(Image)
容器的运行依赖进程命令本身的可执行文件、依赖库和相关资源文件。
为了使不同的容器所使用的这些文件之间能够相互隔离,我们可以利用一种“特殊的文件系统”(前文提到的 namespace 中的一种),即,把可执行文件、依赖库和相关资源文件等都放到该”特殊的文件系统”中,当容器启动后,它只需要读写这部分“特殊的文件系统”即可。
那么,这个“特殊的文件系统”就包含了对容器行为的各种描述,可以认为它就是容器的“模板”,即,这个“特殊的文件系统”长啥样,对应的容器就应该表现出啥样。
如果学习过面对对象相关的内容,可以把这个“特殊的文件系统”与容器的关系类比为类和对象之间的关系。
更进一步地,即使我们在不同的机器上启动容器,只要这个“特殊的文件系统”相同,那么总会得到运行效果完全相同的容器。
在日常使用中,这个“特殊的文件系统”会被打包成压缩包以方便在不同的机器中传递,而这个压缩包被称作“镜像 (Image)”。通常情况下,容器总是从一个镜像启动的。
真正生产环境中所用的镜像不止包含上面提到的这些文件,还会包含一些元信息文件,包括但不限于环境变量、容器启动的入口、容器对外暴露的端口等等。
容器运行时(Container Runtime)
在前面的过程中,我们已经从原理上明白了该怎么把一个程序打包成镜像并进行传输,但是还没有考虑我们应该怎么从镜像得到容器再运行。
并且,同一台机器上可能会启动多个不同容器,有些容器需要动态地停止和启动(比如定时爬取数据),这些工作显然不可能通过手动操作来完成。这是,我们就需要一个工具来帮助我们完成对这些容器的管理工作,我们称这种工具为“容器进行时(Container Runtime)”
容器运行时一般都提供了非常简洁的指令入口,只需要非常简短的命令就可以启动一个复杂的 容器,或者随时停止和重启一个容器。
目前应用最广泛的容器运行时是 runc, 我们常见的各种容器管理工具,如Docker、Podman、containerd等都是以runc为基础构建的。
对,我们的主角docker终于出现了😂
在通常情况下,我们认为Docker、Podman、containerd 等容器管理工具是广义的容器运行时。

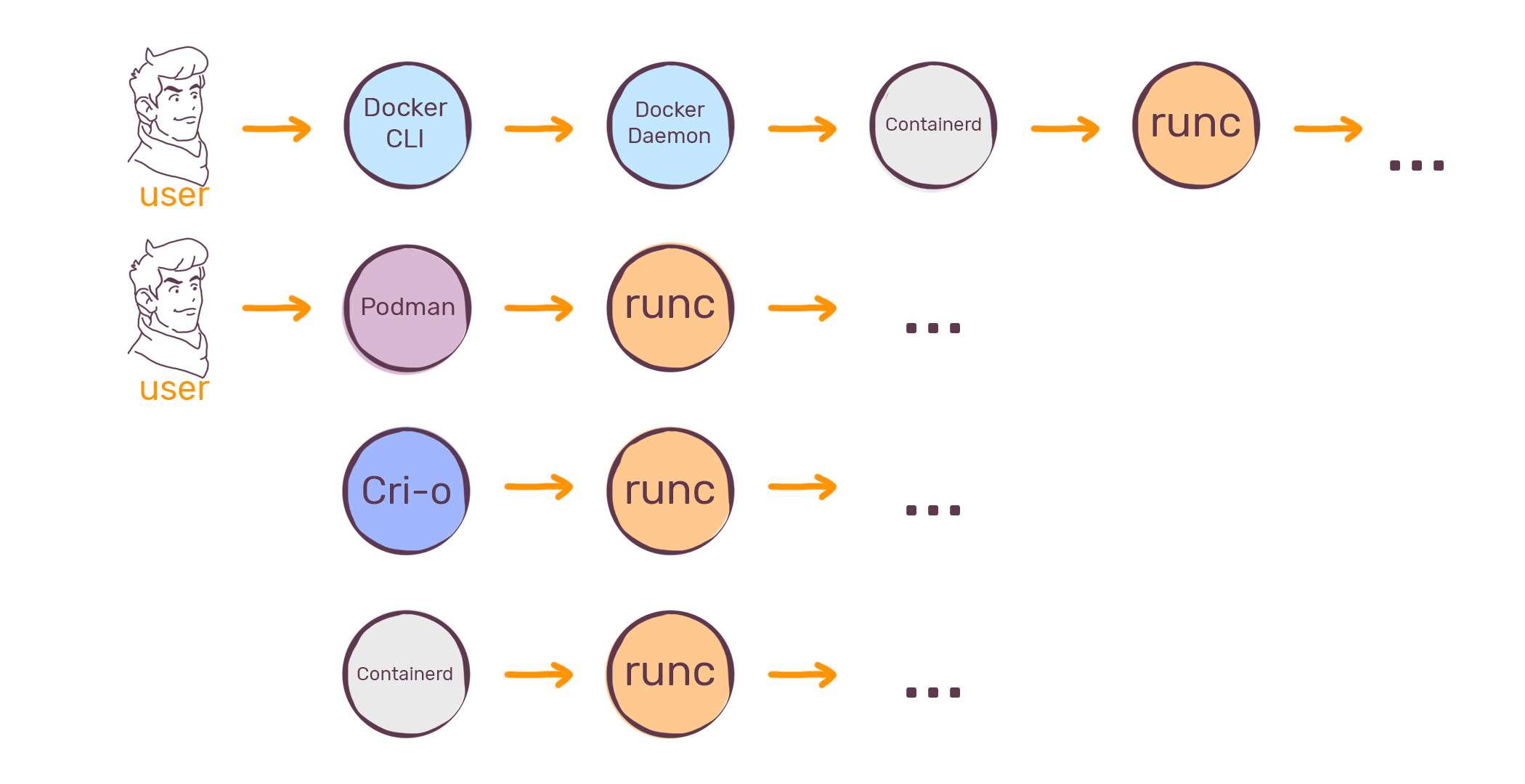
在上面列举的这些容器运行时中,Docker是使用最广泛的容器管理工具,甚至在很多人的认识中,Docker和容器简直就是同义词。虽然Kubernetes将在1.24版本中不再支持使用Docker作为容器运行时,Podman和Containerd也在逐步蚕食Docker的市场,但Docker依然处于垄断地位,很多其他的容器运行时甚至也特意将自己的使用方法设计地和Docker一模一样(如Podman)。
Docker 介绍

上图是Docker的经典Logo, 一个白鲸载着集装箱的形象。”Docker”这个词是从”Dock”演变来的。 Dock 意为“码头”,Docker自然可以引申为“承载集装箱的工具”。”Container”本身也有”集装箱”的含义, Docker作为一个容器 (Container) 管理工具,这样的logo可谓是非常生动形象了。
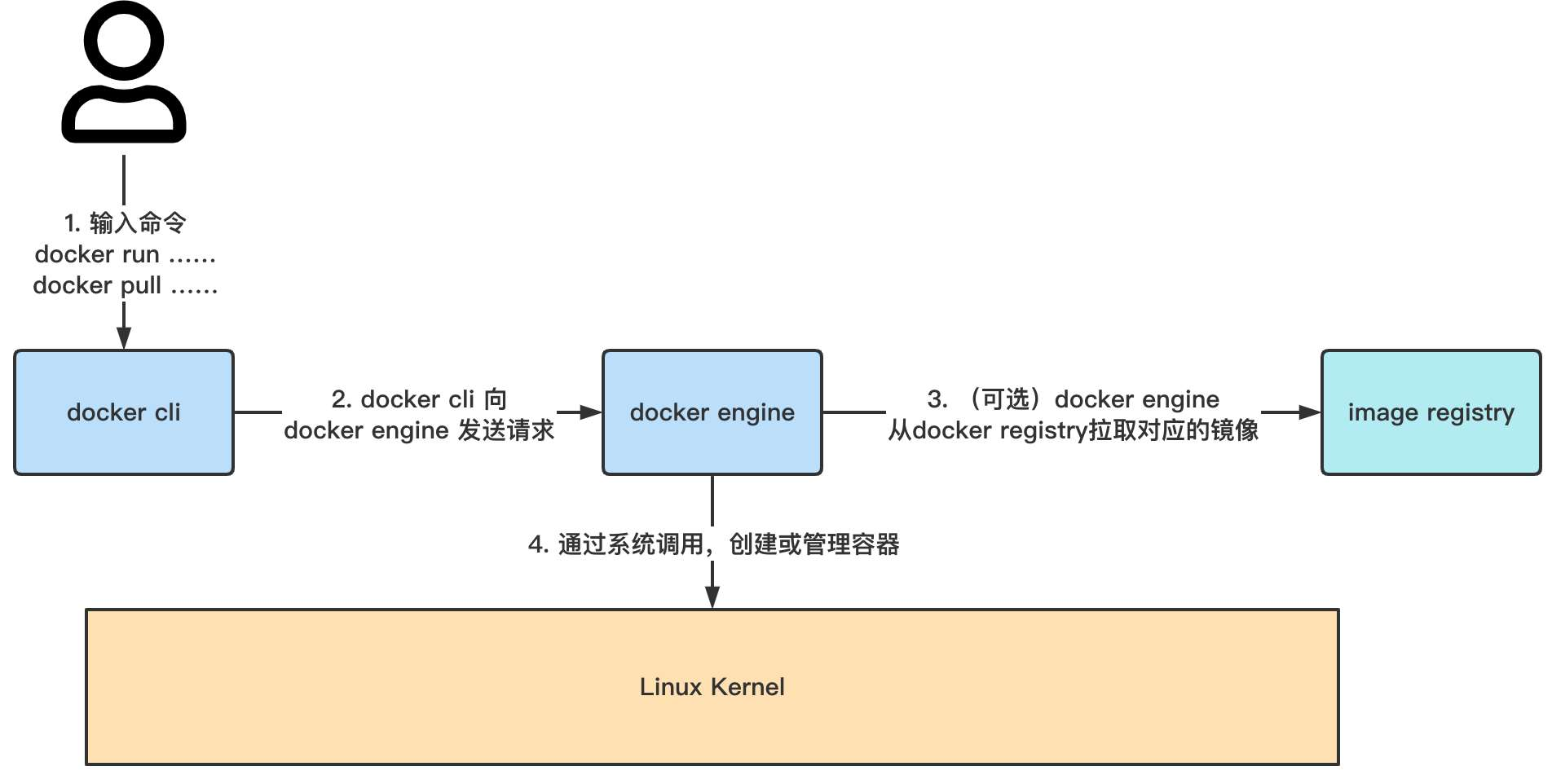
我们平常所说的”Docker”, 其实是一个巨大的结合体。从下图中可以看出,当用户使用Docker 时,要经过多层组件的调用。虽然它们中的很多部分都可以单独作为一个独立软件来用(比如Containerd、runc), 但我们在谈论Docker时,通常认为它们是整个Docker软件的一部分。在 安装Docker时,这些组件也会被同时默认安装。

Docker的安装
Docker 的安装过程如下:
好的,既然大家都已经安装完了 docker ,我们进入下一小节
在这里我们还是简单讲解一下如何在 Windows 中安装 docker~
安装WSL
在前面的原理介绍中,我们介绍过了 docker 的容器功能实际上是利用了 linux 系统中的 namesapce 和 cgroups 机制实现的,因此 docker 并非是一个通用的容器工具,它依赖于已存在并运行的 Linux 内核环境。
docker 实质上是在已经运行的 linux 下制造了一个隔离的文件环境,因此它执行的效率几乎等同于所部署的 linux 主机。
因此,docker 必须部署在 linux 内核的系统上。如果其他系统想部署 docker 就必须安装一个虚拟 linux 环境。
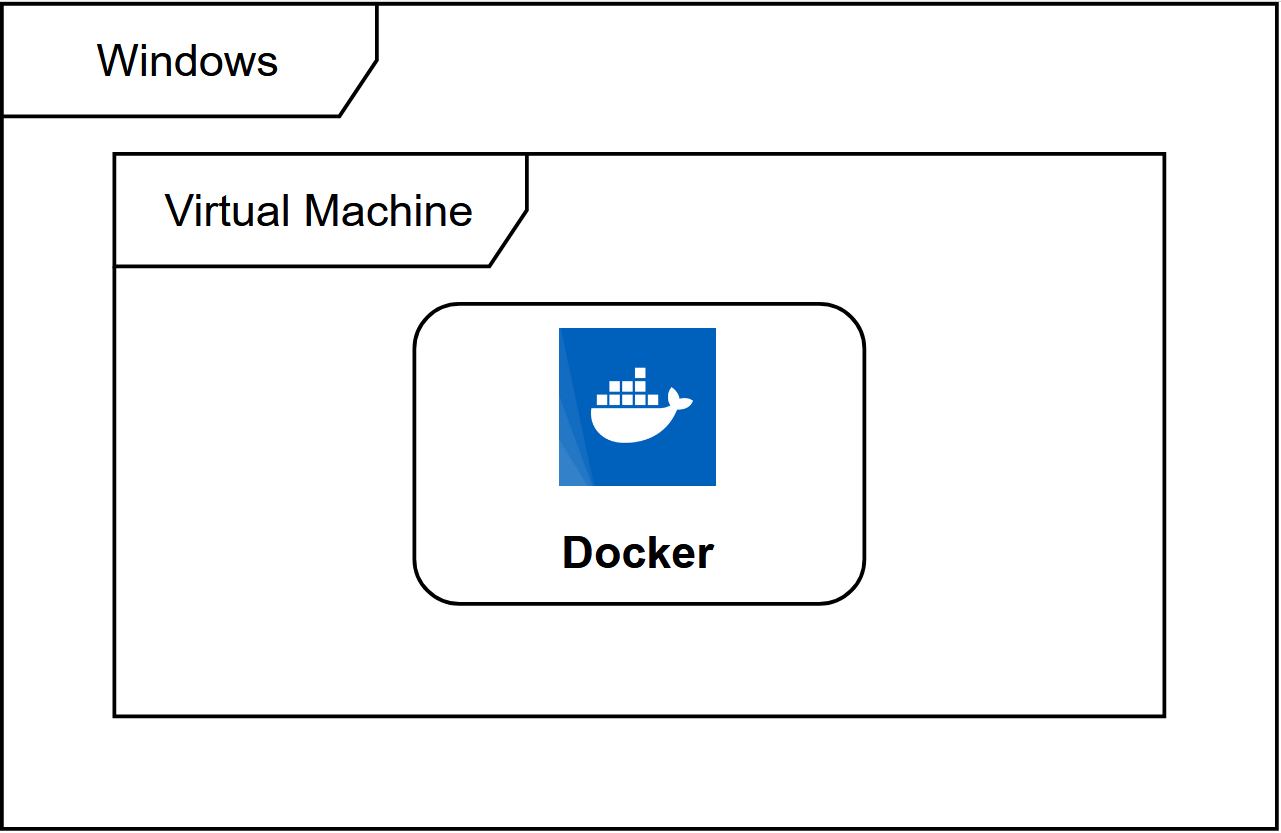
由于 Windows 自带的虚拟机 Hyper-v 需要专业版才能使用,因此我们就不用虚拟机了,而使用 WSL 来准备 docker 运行所需要的环境。
啥是 WSL 呢,它的全称叫 Windows Subsystem for Linux , 也就是 Windows 官方提供的一个子系统,使用户可以在 Windows 系统的电脑上方便的使用一些常用的 linux 软件。这里是它的官方文档。
现在让我们开始安装WSL叭~
首先,我们的操作系统必须是 Windows 10 版本 2004 及更高版本(内部版本 19041 及更高版本)或 Windows 11,否则请考虑升级系统或参考旧版 WSL 的手动安装步骤。
接下来,请右键点击任务栏上的 Windows 徽标(也就是开始菜单栏),在弹出的目录上选择终端管理员。
现在,大家应该已经以管理员身份打开了 Windows 终端 ,也就是在影视作品里常见的黑框框。输入以下命令:
1 | wsl --install |
等待下载完成后重启电脑。
重启后可能会需要输入 UNIX 的用户名和密码,这和后面的 docker 无关,随便输入常用的用户名密码完成注册就可以了。
到这里,docker 安装的第一步就完成了,下一步就是安装docker软件。
安装docker
进入Docker的官网并选择 Download for Windows 下载,下载完成后双击 exe 文件即可进入安装。
安装时记得勾选第一项,即使用我们刚刚安装的 WSL2 而不是微软的 Hyper-V 虚拟机。
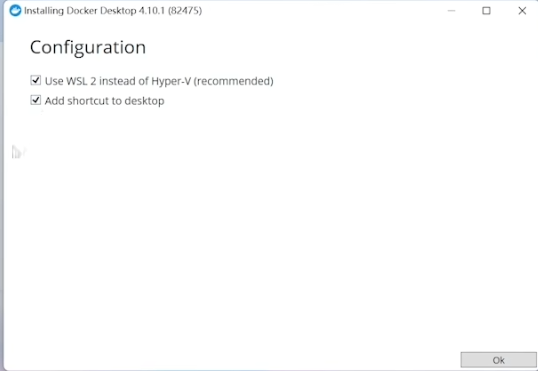
点击 OK 后即可开始安装~
安装完成后,再次重启电脑.会出现 docker 的条款页面,点击接受就能启动 docker 啦!
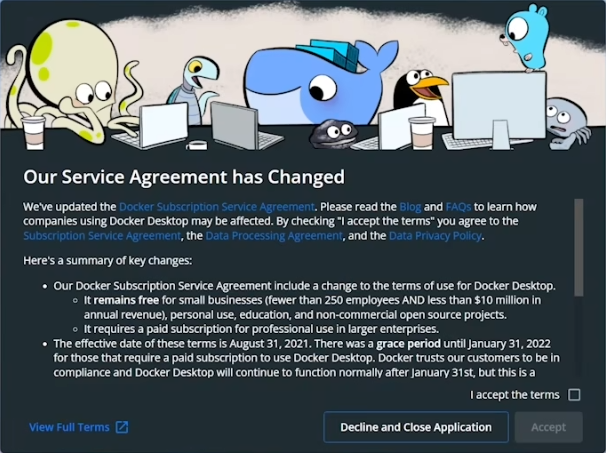
Docker 使用
首次进入 docker ,会出现一个新手教程的页面,请放心,这玩意一点没用(doge)。
修改镜像源
我们先点开右上角的设置,来配置一下国内的镜像源,没错,由于某些原因, docker 的官方镜像源国内同样访问不了。
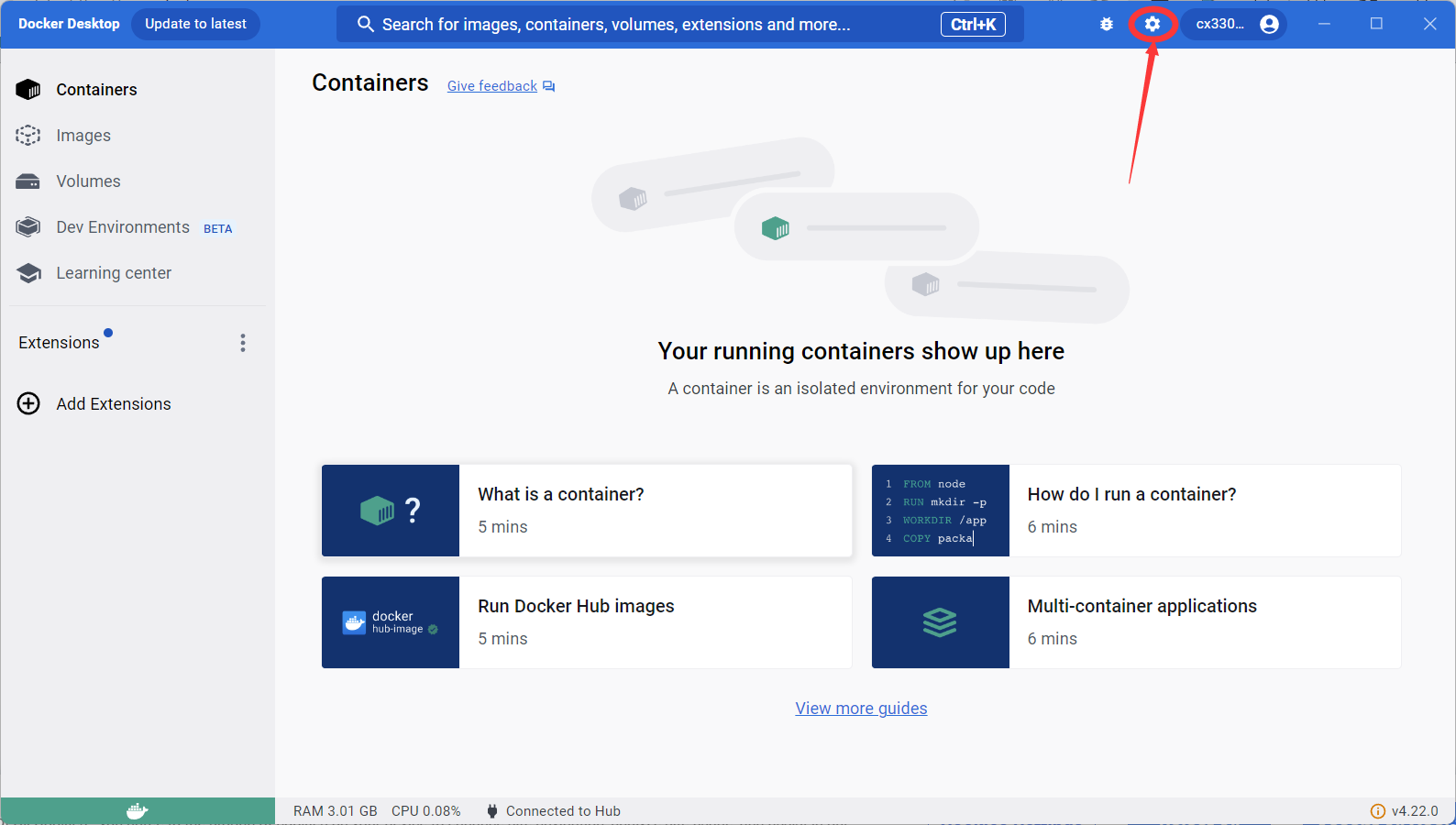
以类似的格式,在 "registry-mirrors" 后面添上需要的镜像源就可以了。一些可能的镜像源如下:
1 | Docker中国区官方镜像 |
Docker 架构
中间的很多过程我也不会,先放张图再这。直接进入下一节吧orz。
Docker Image
我们先直接列出 Docker Image 的常用指令
docker image ls可以列出当前机器的所有容器镜像

docker image pull <image_name>可以从image registry中拉取名称为 image_name 的镜像
镜像名
一般地,镜像名完整格式为 {image registry地址}/{仓库名}/{镜像名}:TAG 。
例如 scs.buaa.edu.cn:8081/library/mysql:8 , 其中:
- scs.buaa.edu.cn:8081/library/mysq1 为镜像的地址,你可以将其简单理解为一个 URL
- 通常情况下,这个地址分为三部分,分别是 image registry 地址、仓库名、 镜像名
- 8是镜像的TAG, 一般用来表示镜像的版本号。
镜像ID
你可能还注意到,当使用 docker image ls时,有一列叫做 IMAGE ID ,这一列中的字符串其实就是每个镜像对应的独一无二的ID,它是一个镜像独一无二的标识。我们可以使用这个ID对镜像做各种操作,比如删除一个镜像: docker image rm b1f7432ce861
image registry
在介绍镜像名称时,同学们可能会疑惑, image registry有很多个吗,为啥还需要地址来标识?
是的,image registry有很多个。 image registry有的是公开的,任何人都可以访问,并从中拉取镜像;也有私有的,需要特殊的口令访问。
目前,世界上最大的几个公开的image registry有 Docker 公司提供的docker.io (目前也是世界上最大、使用最广泛的image registry, 如果你需要通过浏览器访问的话,需要使用这个地址:hub.docker.com )、Redhat 提供的 quay.io、Google 提供的gcr.io (很可惜,这个地址在国内被*了);当然还有我们软院的image registry: scs.buaa.edu.cn:8081。
image registry不仅可以下载已经存在的镜像,还可以上传和保存自己制作的新的镜像。任何人都可以在上述registry网站创建账户和自己的仓库。对于用户上传到image registry中的镜像,用 户可以自行选择是否对其他用户公开访问(公开或私有)。如果是私有镜像,则需要在每次上传和下载镜像前,在本地执行 docker login操作。
容器管理
可以使用 docker ps 命令查看当前机器上处于活跃状态的容器
docker ps -a 可以列出所有状态的容器(包括活跃的和不活跃的):
和镜像一样,每个容器也都有一个唯一的ID作为标识,我们对容器的各项操作也是通过该ID进行的。除了ID之外,每个容器也都有一个独一无二的name, 我们也可以使用 name 来唯一指定一个容器。
在Docker的管理下,容器有以下6种状态:
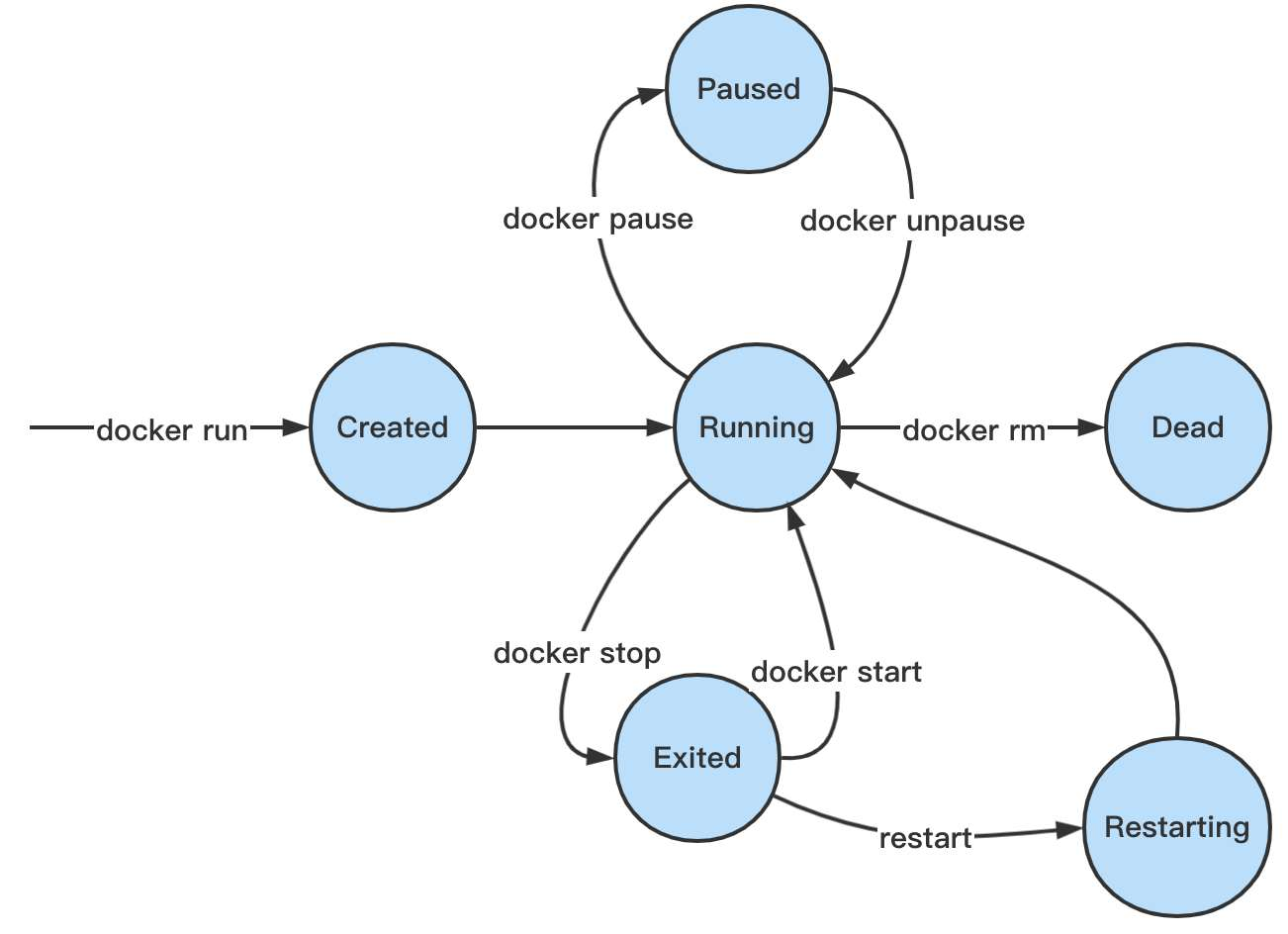
- 当用户输入 docker run 命令后,容器被创建,进入短暂的 Created 状态。
- 当容器进程启动完毕后,容器进入 Running 状态,这表示容器正在正常工作。
- 当用户使用 docker stop 显式地终止一个容器,或容器运行出错时,容器进入 Exited 状态。这个状态是不活跃的,处于这个状态的容器不会消耗任何资源。
- 对于处于 Exited 的容器,可以被手动使用 docker start 重启,重新进入 Running 状态;也可能被 Docker 管理服务重启,短暂进入 Restarting 状态后,重新回到 Running 状态。
- 可以手动使用 docker pause 暂停容器,此时容器将进入 Paused 状态。在这种状态中,容器将停止运行,即不会消耗任何CPU, 但依旧会占据内存(以便随时从这个被 pause 的状态恢复运行)
- 当使用 docker rm 删除容器,但容器中的一些资源依旧被外部进程使用时(即无法立即删除时),容器将进入Dead 状态。
启动容器
docker run 命令的结构是: docker run [一堆各种各样的参数] <image name> [启动命令] [命令所使用的参数] 其中,只有镜像名 image_name 是必须的,其余全是可选的。
启动命令
该部分很无聊,非常无聊
不建议无命令行基础的同志看
即使有基础,如果使用的是Windows或MacOS也不建议看
建议直接看下面的“Docker图形化界面”部分
可以看一下创建这个 docker 镜像时使用的命令: docker run - it --rm ubuntu /bin/bash
这里的参数是-it -rm, 镜像名是ubuntu, 启动命令是/bin/bash, 没有命令参数。
这里/bin/bash 的含义是,启动ubuntu容器后,执行/bin/bash 命令,即启动一个bash shell。我们可以将这里的/bin/bash 换成 ls /usr ,这时,启动命令是ls, 命令参数是/usr, 表示启动ubuntu容器,并在其中执行ls /usr命令,即列出/usr目录下的所有目录和文件。可以看到,执行效果确实如此。并且,请注意,因为我们没有执行/bin/bash 命令,在 ls 命令执行完返回后,并没有进入容器的命令行中,而是回到了宿主机。
-it
参数 i 表示 interactive, 参数 t 表示创建一个虚拟的TTY(pseudo-TTY)。简单来说, -it参数可以让我们进入一个可以与容器进行交互的终端环境。
如果,如果我们在启动命令中去掉-it, 启动的ubuntu容器将会在后台运行,我们将无法和它交互。
—rm
参数—rm 表示当容器退出后,自动删除容器。
如果在执行容器时,不加 —rm 参数,则当从容器退出后,容器进入 Exited 状态,继续存在在机器上(虽然此时为非活跃状态,不消耗任何资源),并且我们可以用 docker restart 等命令重启容器,或使用 docker exec 命令查看容器中的文件。只能使用 docker rm 命令手动删除容器。
-v
到现在为止,我们使用的容器的文件系统都是与宿主机完全隔离的。但在很多时候,容器需要与宿主机共享一些目录,比如位于宿主机上的一些进程希望能方便地看到容器运行中产生的文件,或者通过修改一些文件来影响容器的行为。
为了解决这一问题,我们可以使用 -v 参数将容器的某个目录和宿主机的某个目录绑定起来,使得 容器在读写某个目录时,相当于在同时读写宿主机的某个目录。
参数 -v 的使用方法是 docker run -v <宿主机的目录>:<容器的目录> <image_name>
—name
参数 —name 可以为启动的容器添加名字。我们之前的 docker run 命令都没有使用该参数,那么这时docker自己会为该容器分配一个随机字符串作为name。
Docker图形化界面
其实还有好几个参数,但是实在懒得写了 … 因为,GUI 是人类的伟大发明,既然有 GUI 了谁还用 CLI 啊:
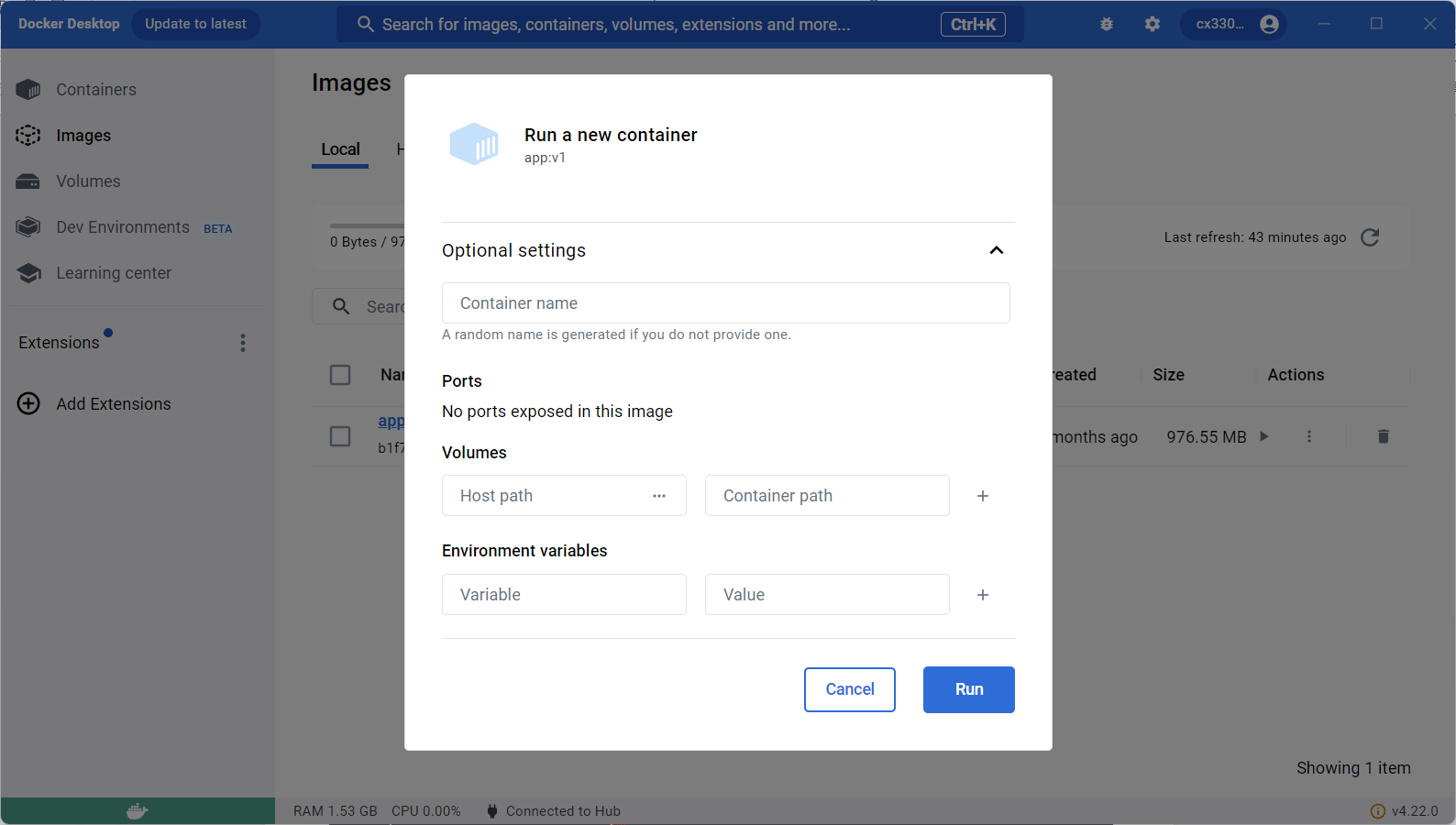
直接点击运行,然后在容器界面:
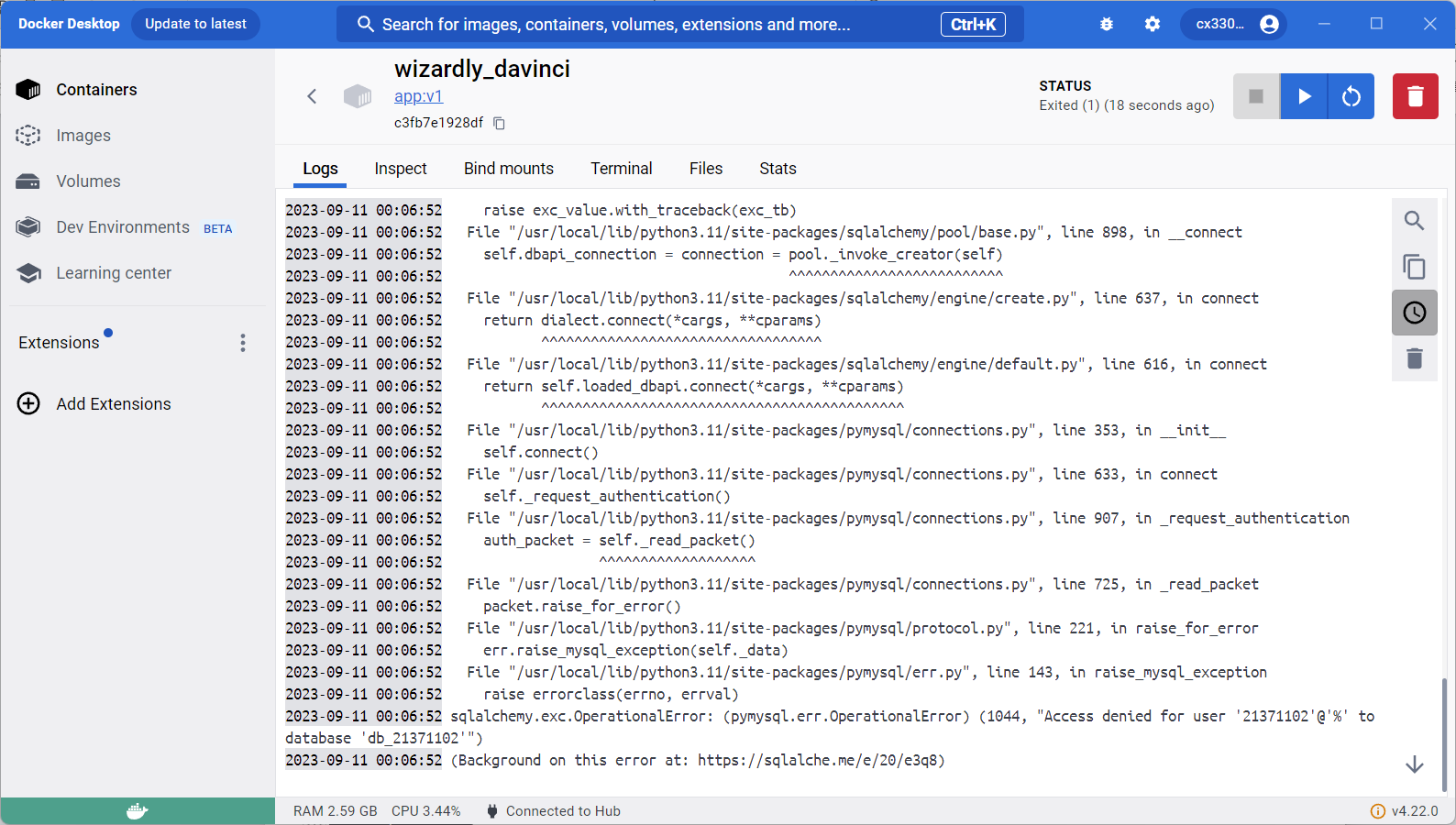
不能说要啥有啥,只能说是应有尽有吧:容器的启动删除、命令行、文件管理、日志,还要啥自行车(图上一堆报错是因为是以前构建的项目,连接的服务器已经关闭了~)
构建新镜像
到现在为止,我们只是在使用他人已经提前做好的镜像。如何制造我们自己的镜像呢?下面给
出两种方法。
docker commit
假设我们正在使用一个容器,并且在该容器的根目录下创建了一个非常重要的数据文件:
如果我想把当前容器的状态保存下来,以便下次启动容器的时候可以重新使用该文件;或者我想把当前容器发送给别人,让别人也看到我当前看到的容器的样子,该怎么办呢?可以使用docker commit 命令将当前容器打包成一个新的镜像。
重新打开一个终端,查看一下当前容器的ID:
然后直接 docker commit <container id><new image name> 即可:
这时,使用 docker image ls 可以看到这个新生成的镜像:
Dockerfile
docker commit 虽然可以非常直观地从当前容器创建一个新的镜像。但整个过程不够规范,也很难实现自动化, 一般情况下,我们都是使用Dockerfile来构建镜像的。
所谓的 Dockerfile , 其实就是一个配置文件,里面描述了构建镜像的步骤。对于我之前完成的一个 Image 的 Dockerfile 文件如下:
1 | from python:latest |
很显然,上述文件内容是自解释的。 一般 Dockerfile 的开头一条 FROM 语句,表示从以哪个镜像为基础进行构建。下面的 RUN 语句表示在容器中执行一条命令。
在工作根目录下执行 docker build -t app:v1 -f dockerfile . 注意最后面的点 “.” 表示当前目录。
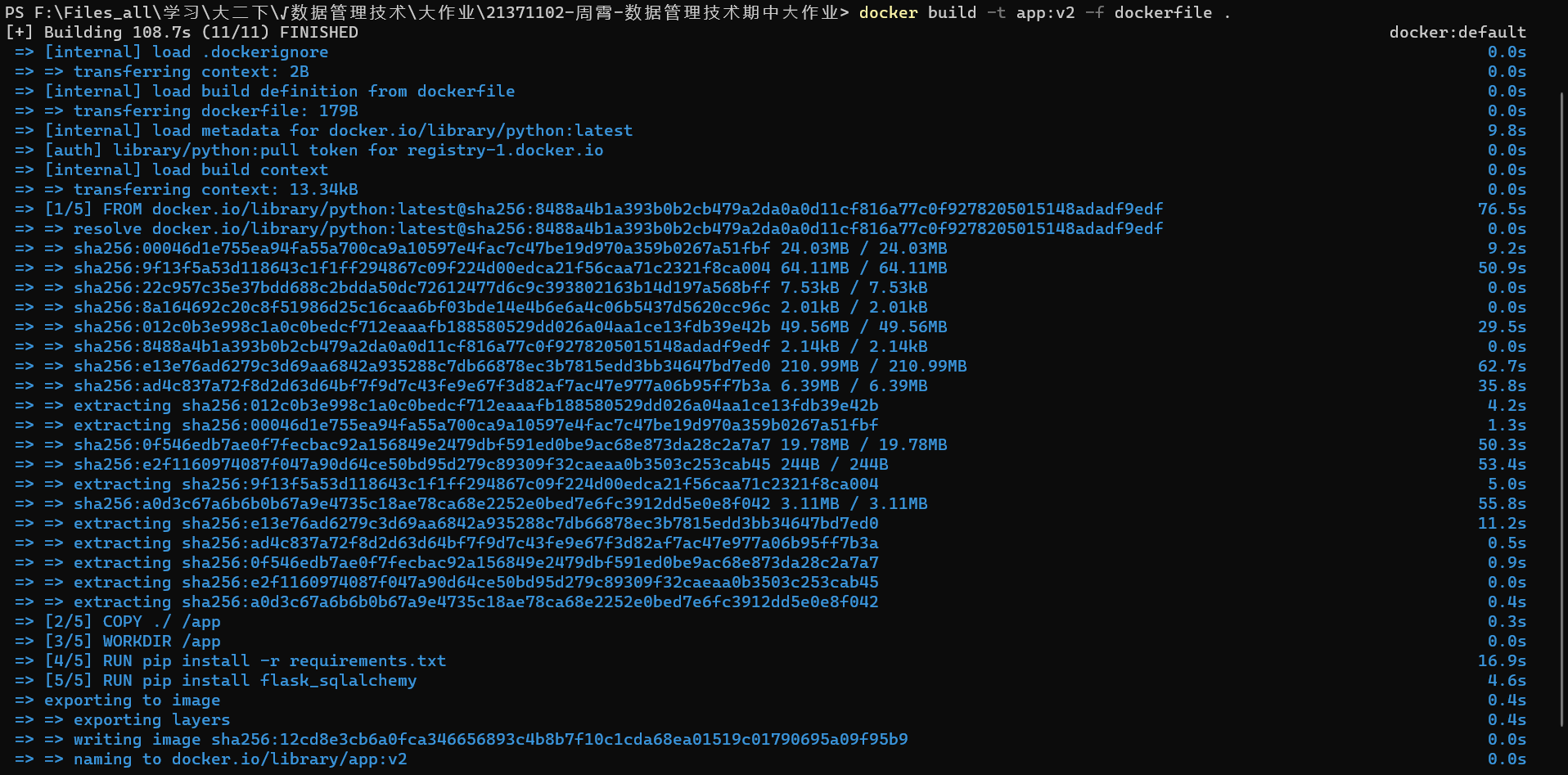
此时,我们就可以在 docker 的GUI界面上看到新的镜像了:
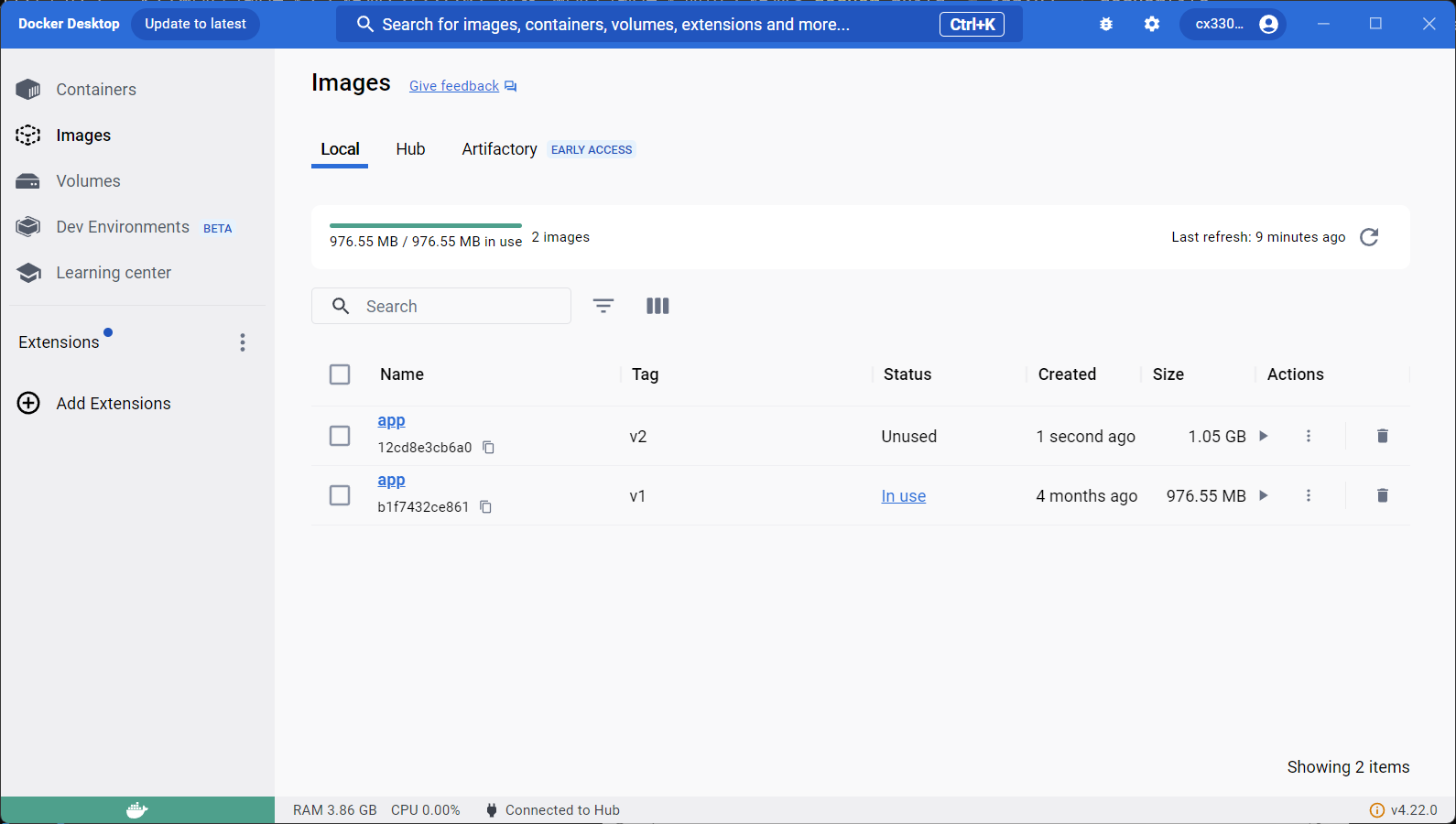
- -t 表示要构建的新的镜像的名称
-f 表示Dockerfile文件的路径
命令中最后的单词表示表示构建镜像的上下文路径,上图中这个最后的单词是.,则表示 上下文路径是当前目录。在镜像构建开始的时候, docker cli会把“上下文路径”指定的目录 中的所有内容打包,然后整个发送给docker engine。
事实上, Dockerfile 还支持非常多的指令,具体请查阅官方文档。
发布镜像
截止目前,我们构建的镜像全是在本机上,别人根本访问不到,也没法使用。我们可以将镜像 push 到 image registry 上,然后通知对方从该image registry拉取即可。具体可以使用GUI中的 push 操作,也可以参考官方文档了解CLI的 push 过程。
云实例
书上使用了 DigitalOcean 构建云实例,但是我刚注册好它就让我绑定银行卡,而且需要 VISA 卡或者 PayPal … 所以我准备直接用我自己的腾讯云服务器进行部署。
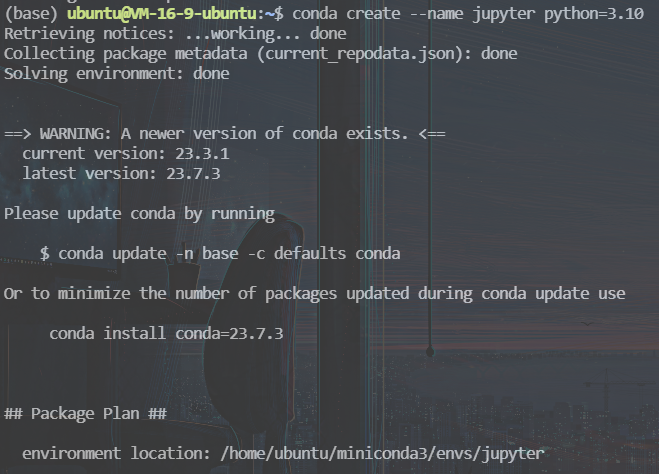
首先,我们来新建一个叫 jupyter 的conda虚拟环境,python版本为3.10
进入该环境后,安装 jupyter notebook 的软件包。
1 | pip3 install ipython |
新建一个文件夹,作为 jupyter notebook 的工作目录,并进入该工作目录。
1 | mkdir jupyter_notebook |
首先,我们生成 jupyter_notebook 的配置文件。
1 | jupyter notebook --generate-config |

我们会看到,系统输出了配置文件所在的路径,先记住它,等会要用。
接下来我们设置密码,输入 jupyter server password 后回车,输入两遍密码即可。

这里又生成了一个配置文件,我们通过 vim 命令访问一下。
可能有对 vim 不熟悉的同学,这是一个很nb的编辑器。有很多指令,可以在Vim 编辑器 - 基础入门_vim入门_Amentos的博客-CSDN博客学习一下~
1 | vim /home/ubuntu/.jupyter/jupyter_server_config.json |

我们看到了一串 argon2 或 sha1 开头的哈希密码,这取决于 jupyter 的版本,在新版本的 jupyter 中采用了更安全的 argon2 算法来生成密码,我们把双引号内的哈希密码复制,并退出该文件。
接下来编辑最开始的配置文件:
1 | vim /home/ubuntu/.jupyter/jupyter_notebook_config.py |
在文件的底部添上以下的五行代码。
1 | c.NotebookApp.ip='*' # *代表所有机器都可访问,或者输入服务ip |
按 esc 后输入 :wq 保存并退出。
接下来就可以运行啦!输入 jupyter notebook 命令即可将 jupyter notebook 在 8888 端口运行。(记得在服务器防火墙打开 8888 端口)。
在浏览器中输入 ip地址:8888 即可进入jupyter notebook的登陆页面。
输入密码后即可看到我们的工作目录并开始写代码啦。
当然,此时我们的服务器命令还一直在运行着jupyter服务,感兴趣的同学可以研究下Tmux让它一直在后台运行~
总结
四个模块的内容终于全部讲完了,其实可以很清楚的发现,docker讲的最多,但是也最乱,毕竟笔者自己也用的很少QAQ。
实际上对于非科班的同学来说,docker和云实例的使用相对较少(该不会真有人为了可以在浏览器里用 jupyter notebook 就化几百块一年买个服务器吧doge),而 pip 和 conda 虚拟环境其实就已经满足了绝大多数的生产需求。






